


Are there ways of segmenting the data in SQL Server, so that you only backup and restore the data you care about? The simple answer; yes. We’re going to focus on these methods to speed up your SQL Server database backup and restore processes.
If you frequently need to restore production databases into QA/dev environments, but are frustrated by how long it takes, these tips are aimed at you. Alternatively, as part of our SQL Server Health Check, we’ll take a deep dive into your database for you, and produce an analysis and reports to help you get the most out of your SQL Server database.
Move Large Tables Into a Separate Database Without Breaking Your Applications
It is very common for databases to contain ‘audit’ or ‘history’ tables. As the name suggest, these tables are typically used for tracking system activity, for auditing compliance reasons. Corporate data retention policies can often mean that historical data must be retained (7 years seems to be the standard!) and therefore the size of these tables increase over time, often reaching 100’s of GB (or even several TB) in size.
By default, these tables will be part of your database backup, and good practice tells you that they should be.
However, when it comes to restoring your databases into QA/Dev environments, the huge amount of data in these ‘audit’ tables is typically not required, yet because it’s all part of one backup file, you have no choice but to backup and restore the whole thing.
Therefore, a question that you may ask is:
“Can I move these tables into a separate database without breaking my applications?”
Fortunately, yes! By using one of SQL Server’s least-used features – Synonyms, you can move these ‘audit’ tables to a separate database, without having to rewrite database procedures or application code.
Example
We’re using the 10GB version of the Stack Overflow database, which has been modified to include an extra (fictional) table name ‘Audit’. This table keeps track of activity in the system and is growing significantly over time.
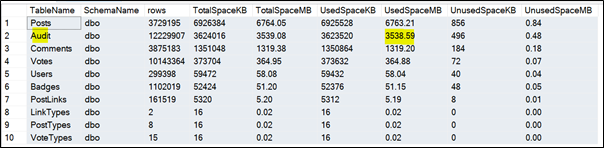
As seen above, the ‘Audit’ table is second only to the ‘Posts’ table in size. Imagine that you’re frequently restoring this database into QA/Dev environments. It doesn’t really help with testing or development, and we don’t need those GBs of historic data. However, we do need the table to exist for our applications to work.
If you can move the ‘Audit’ table into a separate database, you can backup and restore the rest of the database, independently of this ‘Audit’ database.
We can achieve this in three (relatively) simple steps.
Step 1 – Create a New Database With a Blank Copy of the ‘Audit’ Table(s)
CREATE DATABASE StackOverflow2010Audit
GO
USE StackOverflow2010Audit
GO
CREATE TABLE [dbo].[Audit](
RecordId[int] NOT NULL,
UserId INT NULL,
[Date] [datetime] NULL,
[AuditText] NVARCHAR(MAX)
)
GO
Step 2 - Insert the Existing Data Into the New Database
INSERT INTO [StackOverflow2010Audit].[dbo].[Audit]
SELECT [A].[RecordId],
[A].[UserId],
[A].[Date],
[A].AuditText
FROM [StackOverflow2010].[dbo].[Audit] AS [A];
Step 3 - Drop the Table and Replace It With a Synonym
USE [StackOverflow2010]
GO
DROP TABLE [dbo].[Audit]
GO
CREATE SYNONYM dbo.Audit FOR [StackOverflow2010Audit].[dbo].[Audit]
All the queries that reference dbo.Audit will now point to the new table in the new database. However, the database maintenance operations against the StackOverflow2010 database, such as CHECKDB, and crucially in our case, backups and restores, will now be faster.
The Downside
The main drawback of this approach relates to referential integrity. Foreign Key (FK) constraints don’t work across different databases, so you need to drop them and manage your referential integrity a different way.
Furthermore, FK constraints are used by the query optimiser when building a query plan, so monitoring the performance impact on your most expensive queries is important.
It’s also another database that you’ll need to manage and maintain! You’ll still want to backup the ‘Audit’ database and perform maintenance operations.
Finally, don’t forget to test that your applications continue to function properly, and that they have appropriate permissions to the new database (where required).
If you need assistance with your databases, Koderly are here to help. Visit our services page for more information on how we can support your SQL Server instances and databases.
In our next post in this series, we’ll cover how partitioning can be used to segment your large tables into their own filegroups for backup and restore purposes.
Thanks for reading!
