


“When storing an email address in a SQL Server table, is it more performant to store it as a hashed value rather than plain text?”
This question was asked by one of our Remote Database Administration clients, to much speculation around the (remote) office. So, let’s find out by generating some data and running some simple tests.
First things first:
- We’ll use the 50GB version of the StackOverflow2013 database, which contains 2.3million user records. You can get from here if you want to try this out yourself.
- These tests are carried out using SQL Server 2019, compatibility mode 130 (2016). However, I’ve not found the version or compatibility mode to make a notable difference.
SET UP OUR DATA
Those smart folks over at StackOverflow clear out the email addresses from the Users table before providing the backup, so we’ll need to generate some new ones to carry out these tests. First, let’s add a couple of columns; one to store a plain text email address and a second for the hashed version. We’ll hash the email address using the HASHBYTES function and the SHA2_256 algorithm, which generates a VARBINARY(32) hash. The regular email address is a straight-forward VARCHAR(32):
ALTER TABLE dbo.Users ADD Email VARCHAR(32) NULL;
GO
ALTER TABLE dbo.Users ADD EmailHash VARBINARY(32) NULL;
Next, let’s populate our new columns. We want realistic data for our email address and one way of generating this is by combining the user’s ID and name (the ID ensures uniqueness, which makes sense for an email address). In this first test, I’m also going to trim the length, just so we don’t hit any capacity errors:
UPDATE dbo.Users
SET Email = LEFT(CAST(Id AS VARCHAR) + REPLACE(DisplayName, ' ', '') + '@test.com', 32);
…and now, let’s create the hashed column, based on our regular email column:
UPDATE dbo.Users
SET EmailHash = HASHBYTES('SHA2_256', Email);
Finally, we’ll create an index on each column to support our search query:
CREATE NONCLUSTERED INDEX [IX_Users_Email]
ON [dbo].[Users] ([Email]) INCLUDE(DisplayName, UpVotes)
CREATE NONCLUSTERED INDEX [IX_Users_EmailHash]
ON [dbo].[Users] ([EmailHash]) INCLUDE(DisplayName, UpVotes)
Test 1 – Performance test on a typical email address
Now that our data is all set, we’ll perform a simple search to find a user record by email address. We’ll search against both the plain-text column and the hashed column so we can compare performance.
SELECT ID, DisplayName, UpVotes FROM Users WHERE Email = '99joebloggs@test.com';
SELECT ID, DisplayName, UpVotes FROM Users WHERE EmailHash = HASHBYTES('SHA2_256', '99joebloggs@test.com');
The execution plans are identical (index seek), as is the CPU time and number of reads:
Table 'Users'. Scan count 1, logical reads 3, physical reads 0…
Table 'Users'. Scan count 1, logical reads 3, physical reads 0…
So no real difference, right? Well let’s take a closer look at the indexes that we created above by running the following query. Note that you’ll need to change the index_id value (6 below) to match the ID of your index (you can find this by querying sys.indexes).
SELECT [index_id],
[index_level],
[record_count],
[page_count],
[avg_record_size_in_bytes],
index_type_desc
FROM [sys].[dm_db_index_physical_stats](DB_ID('StackOverflow2013'),
OBJECT_ID('Users'), 6,NULL, 'DETAILED')
WHERE [alloc_unit_type_desc] <> 'LOB_DATA'
AND [page_count] > 0

Notice the page_count and avg_record_size_in_bytes columns. The index on our hashed column (index_id=7) contains more pages due to a slightly larger record size. With a larger dataset, those extra pages could result in extra reads, and if our table had 100,000,000 users, that could start to hurt overall performance.
TEST 2 - PERFORMANCE TEST ON A LARGE STRING
Most email addresses are around 20 characters long, and my test above has shown that in that scenario, hashing doesn’t appear to gain you anything performance-wise (at least when measured by reads). However, what if you’re hashing a much larger string, say, 300 bytes?
Let’s quickly run the example again, but this time we’ll increase the column sizes of our regular Email column and force the data to fill it by padding out the value in both. However, we can leave the hashed column as a VARBINARY(32):
ALTER TABLE dbo.Users ADD Email VARCHAR(300) NULL;
GO
ALTER TABLE dbo.Users ADD EmailHash VARBINARY(32) NULL;
GO
UPDATE dbo.Users
SET Email = CAST(Id AS VARCHAR) + REPLACE(DisplayName, ' ', '') + '@test.com';
-- Expand the email address to fill the column
UPDATE dbo.Users
SET Email = Email + REPLICATE('x', 300-LEN(Email));
-- Hash email address
UPDATE dbo.Users
SET EmailHash = HASHBYTES('SHA2_256', Email);
-- Create our indexes as before
CREATE NONCLUSTERED INDEX [IX_Users_Email]
ON [dbo].[Users] ([Email]) INCLUDE(DisplayName, UpVotes)
GO
CREATE NONCLUSTERED INDEX [IX_Users_EmailHash]
ON [dbo].[Users] ([EmailHash]) INCLUDE(DisplayName, UpVotes)
GO
Here’s a snippet of our data:

Note how although we had to increase the size of the email column to accommodate the larger string, the hashed string still fits within the EmailHash VARBINARY(32) column. Now, when I perform a search with a super-long string as the predicate, the non-hashed search (top result) is reading more pages:
Table 'Users'. Scan count 1, logical reads 5, physical reads 0…
Table 'Users'. Scan count 1, logical reads 3, physical reads 0…
A look at the index structure shows why. The average size of the VARCHAR records has increased significantly, whereas the VARBINARY records remains the same as the previous test. This increase has resulted in additional levels in the index, meaning even when it seeks, SQL Server is performing additional reads compared to the index on our hashed column:
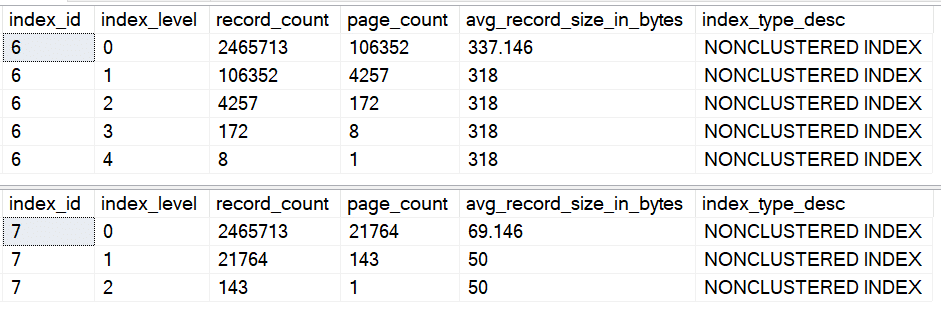
Again, think about how this looks with 100,000,000 records in the table. Consider the impact this will have on not only the number of reads, but also the memory grant and CPU time.
CONCLUSION
Focussing on the original question – When storing an email address in a SQL Server table, is it more performant to store it as a hashed value rather than plain text?
Providing you index correctly, then the simple answer is no. In fact, if your data set is large enough, hashing is more likely to cause additional reads that may actually hurt performance.
However, if dealing with larger string data, the shortened hashed key will likely result in fewer reads for your queries. Of course, the best way to prove this is to test it on your own dataset.
On final point – you may have landed on this blog because you’re concerned about GDPR and have heard that hashing is a good way to hide sensitive data. Whilst true, don’t forget that later versions of SQL Server come with features such as Dynamic Data Masking, that were specifically built with GDPR problems in mind.
Thanks for reading!
